

Спикер: Антон Дёкин, ведущий зоотехник KSITEST.
Модератор: Дарья Яковишина, генеральный директор и сооснователь KSITEST.
Чтобы принять участие в практической международной конференции KSIDAY 2022, которая в этом году пройдёт 2 ноября, подавайте заявку на подключение к онлайн-трансляции мероприятия по ссылке: https://ksiday.ru/.
Антон:
Что расскажем сегодня?
- Какие интересные данные получили на нашей популяции и в целом про то, что узнали за два года работы в России.
- Что получили по точности, наследуемости, инбридингу на нашей российской популяции — это уникальные данные, которых нигде никогда не было.
- Какие оценки у нас сейчас есть, как посчитали корреляцию оценок в CDCB и какое распространение генетических заболеваний есть в российской популяции.
Что у нас уже есть?
На данный момент мы обладаем самой большой базой генотипов, которую составляет почти 20 000 животных. Работаем в 9 регионах нашей большой страны, а также являемся единственным в России и СНГ аккредитованным центром ICAR по интерпретации ДНК-данных. Всего таких организаций 23 в мире, и мы одни из них.
Для того чтобы разобраться, из чего складывается геномная оценка, нужно понять, что для этой оценки нужно. Для оценки нужно в целом 3 группы показателей:
- фенотипы — данные об осеменении, отёлах, молочной продуктивности;
- родословные животных, чтобы у нас были какие-то родословные связи между животными;
- генотипы.
Данные фенотипов связываем с данными генотипов, чтобы в будущем можно было по генотипу родившегося животного сразу же выдать ему оценку высокой точности. Данные по родословной нужны для того, чтобы улучшать качество этой оценки, чтобы у неё была более высокая точность.
На первом этапе нужно было собрать единую референтную базу — единую родословную, чтобы:
- исключить повторяющихся животных, чтобы они не учитывались 2 раза;
- получить более высокую точность, так как у нас есть какое-то общее условное родословное древо животных — кто от кого произошёл.
Для того чтобы получить единую родословную, нужно было идентифицировать всех животных и проверить их на дубли. Повторяющихся животных слить между собой и получить достоверные данные. После всей этой процедуры животные получают свой уникальный код и уже никогда не будут задвоенными.
Для точности определения родословных нужно было подтверждение происхождения. Подтверждение происхождения мы проводим по методике ICAR, по геномным данным, которые являются стопроцентно надёжным методом подтверждения происхождения.
Первые интересные результаты на нашей популяции.

Обнаружили, что в наших хозяйствах конфликтов неверных записей отца — на уровне 9%, а по матери около 7,5%. В целом достойный показатель, это не так уж плохо. Было медицинское исследование, которое проводило подтверждение родства в разных популяциях, и получился результат от 4 до 15% в зависимости от популяции, страны и метода получения подтверждения происхождения. Так что в целом у нас конфликты находятся на среднем уровне — ни хорошо, ни плохо. Но нужно помнить всё-таки о том, что подтверждение родства — очень ценное и важное событие. Потому что неверное подтверждение родителей приводит к тому, что идёт неконтролируемое увеличение инбридинга, снижается племенная ценность животного. Поскольку нет понимания, кто точно у него родитель, и в целом снижается селекционный ответ от намеченной стратегии.

На следующем этапе мы должны были отфильтровать фенотипы, чтобы исключить какие-то случайные выбросы и явно ошибочные данные, чтобы эти данные в последующем не участвовали в расчёте оценок животных. Например, можно назвать межотёльный интервал — у нас норма 365−385 дней, а при этом достоверный интервал мы учитываем от 300 до 350 дней. Ну, и так далее по всем остальным показателям, которые используем. Есть какой-то доверительный интервал, где мы понимаем, что данные достоверны, а за пределами этого интервала точно не достоверны.
Это был подготовительный этап. Для того чтобы понять, как провести оценку, мы должны разобрать каждую оценку по шагам.

Шаг 1. Выбираем подходящую модель для типа данных. Есть некоторое количество моделей, которые рассчитывают математические оценки животных. При этом они отличаются не только разным подходом, но и разными данными, которые используют. Например, есть модели специально для количественных признаков, типа удоя молока, есть для бинарных признаков, например выживаемости, для линейных признаков, например экстерьера. Мы должны были выбрать подходящую модель для признака или несколько подходящих моделей для этого признака.
Шаг 2. Запускаем и подбираем фиксированные эффекты, которые влияют на этот признак. Например, сезон, год, отёл, год лактации и так далее. То есть различные внешние факторы, которые в сумме влияют на всю группу, — это будет группа фиксированных эффектов. Выявляем значимые фиксированные эффекты для этого признака.
Шаг 3. Учитываем reliability (достоверность). У нас получился один признак в разных моделях с разными фиксированными эффектами. Мы можем посмотреть, насколько высокая надёжность при разных подходах для этого признака.
Шаг 4. Рассчитываем корреляцию между самими признаками. Например, между разными признаками нашей оценки, или считаем корреляцию с оценкой, например, других стран.
После того как всё это провели и удостоверились в том, что наша оценка лучше, чем может предложить кто-либо ещё, — можем добавить эту оценку в наш индекс. На данный момент у нас есть девять оценок по шести признакам, которые представлены на слайде.

Разберём путь, как проходит оценка, на примере молочной продуктивности.
У нас получилась модель с определёнными фиксированными эффектами, и мы получили reliability (достоверность). Что такое reliability? Reliability показывает, насколько оценка животного близка к его истинной племенной ценности. Именно не к фенотипу животного, а к его истинной племенной ценности.
На этом этапе нужно понять, какое значение является хорошим или плохим. Если это бык-производитель, у которого есть несколько сотен потомков в нескольких десятках стад, то его оценка может достигать достоверности 0,95−0,99. Это означает, что мы уже довольно точно знаем, что от этого быка получается, и новые данные по этим потомкам особо не будут менять оценку этого быка.
Дарья:
Что сейчас мы видим на слайде, что это за такие сложные графики, и почему их так много?

Понятно, что чем лучше у вас данные, тем лучше будет предсказание, тем выше будет достоверность данных. Каждый график показывает разные хозяйства. Видно, что какие-то хозяйства лучше записывают данные, поэтому у них такая высокая оценка. Какие-то записывают данные немного хуже, поэтому у них оценки в среднем на 10−15% ниже, чем у других. Мы видим, что действительно важно то, как вы ведёте данные. Но при этом для всех этих данных рассчитаны оценки по молочной продуктивности. Средняя точность оценки у нас примерно 0,72.
Антон:
Медиана оценок 0,72 — для коров это очень хороший показатель. Поскольку у нас нет, как у быков, нескольких сотен потомков от одной коровы.
Что такое достоверность 0,7, и как это можно чуть проще объяснить?

На слайде изображено три графика: достоверность 0,3, 0,5 и 0,7. Это означает, что при большей достоверности будет меньший разброс оценки относительно её истинной племенной ценности. Если достоверность низкая, например 0,3, то у животного может быть довольно большой разброс фактических значений её ценности. Здесь хотелось бы отдельно отметить, что достоверность 0,5 означает окно, в котором есть какое-то стандартное отклонение. Чем выше достоверность, тем ниже это отклонение.
Дарья:
Мы взяли средние данные по всем нашим хозяйствам, их оценкам и взяли стандартное отклонение. Много хозяйств нас спрашивают: что такое достоверность, что это значит — 0,5 и 0,7? И здесь мы прямо привели, откуда это берётся и что это значит. Достоверность 0.5 показывает нам, в каком интервале находится оценка. Когда у нас базис, например, 6 000 кг, оценка +500, это значит, что истинная оценка животного может варьироваться от 6 000 до 6 700. То есть не может быть такого, что у нее 3 000, например.
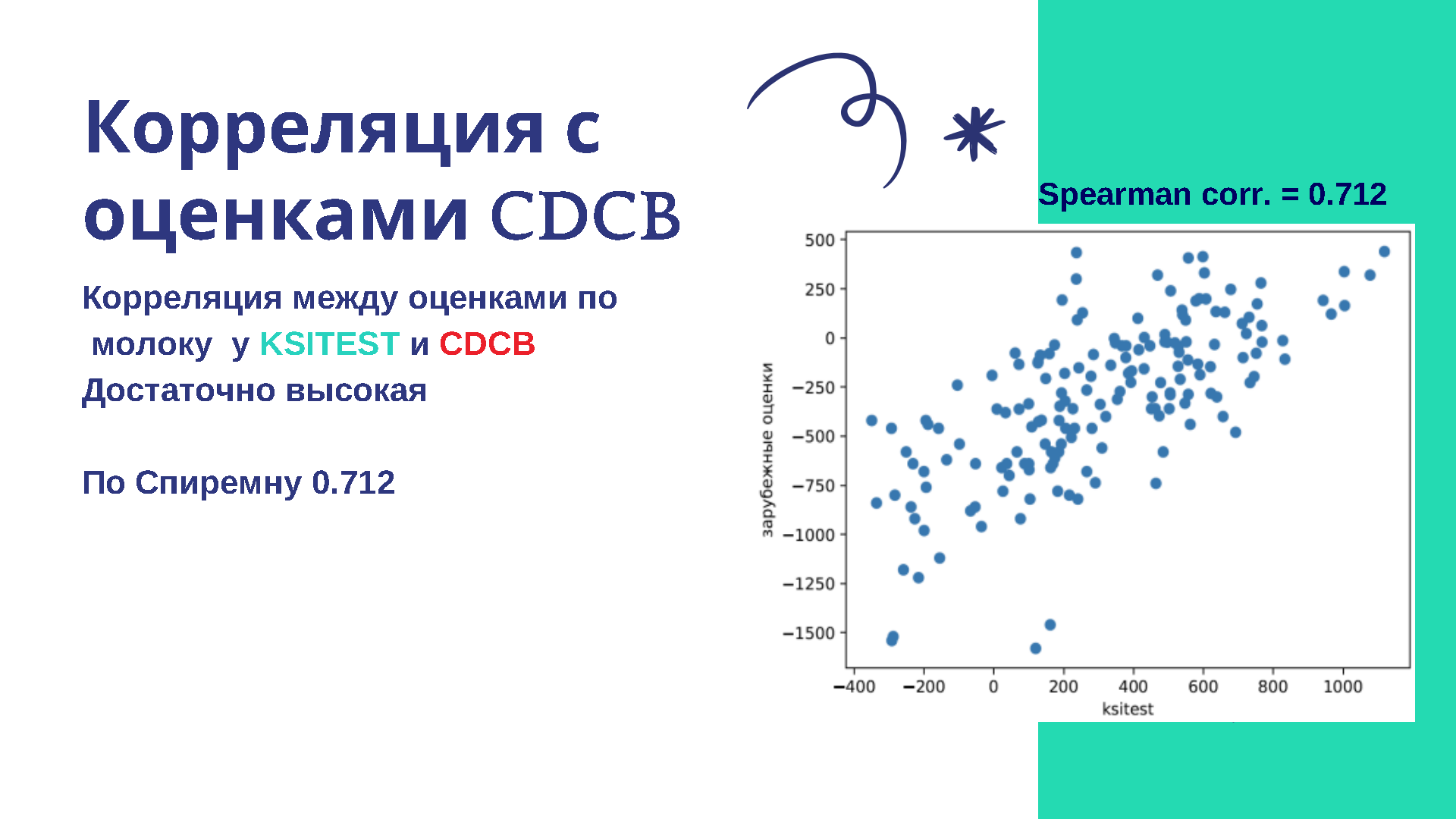
Антон:
На следующем этапе мы можем провести корреляцию с оценками какой-нибудь другой страны, например, с CDCB. Поскольку мы чаще всего встречаемся с американской оценкой, и плюс у нас есть несколько клиентов, которые в итоге ушли от оценки CDCB и оценивают по российской базе.
Соответственно, у нас есть оценка CDCB, наша оценка и фенотипы животных. Мы можем проверить непосредственно на живых животных, кто оказался лучше. Корреляцию мы провели между нашими оценками по молоку и оценками CDCB. Получили следующий результат: довольно высокая корреляция между нашими оценками и оценками CDCB.
Дарья:
Мы, конечно, знаем, что у CDCB самая большая база в мире, у них накоплена огромная референтная база, несколько миллионов генотипов, и коллеги работают в этом направлении очень много лет. Не хотим сказать, что мы пришли и сделали всё лучше. Дело не в этом. Здесь скорее про запись данных — какие у нас есть данные. Важная вещь, которую хочется показать этим графиком, что у нас одни и те же коровы, те же самые голштины, похожая популяция, похожие быки, то есть у нас много общего. Именно поэтому мы видим высокую корреляцию между нашими оценками и их оценками. Нет такого, что у нас абсолютно разные животные, и как бы всё не так. Конечно, нет. Есть общий тренд между нашими оценками и их оценками — это самое главное, что мы хотели показать на этом слайде.
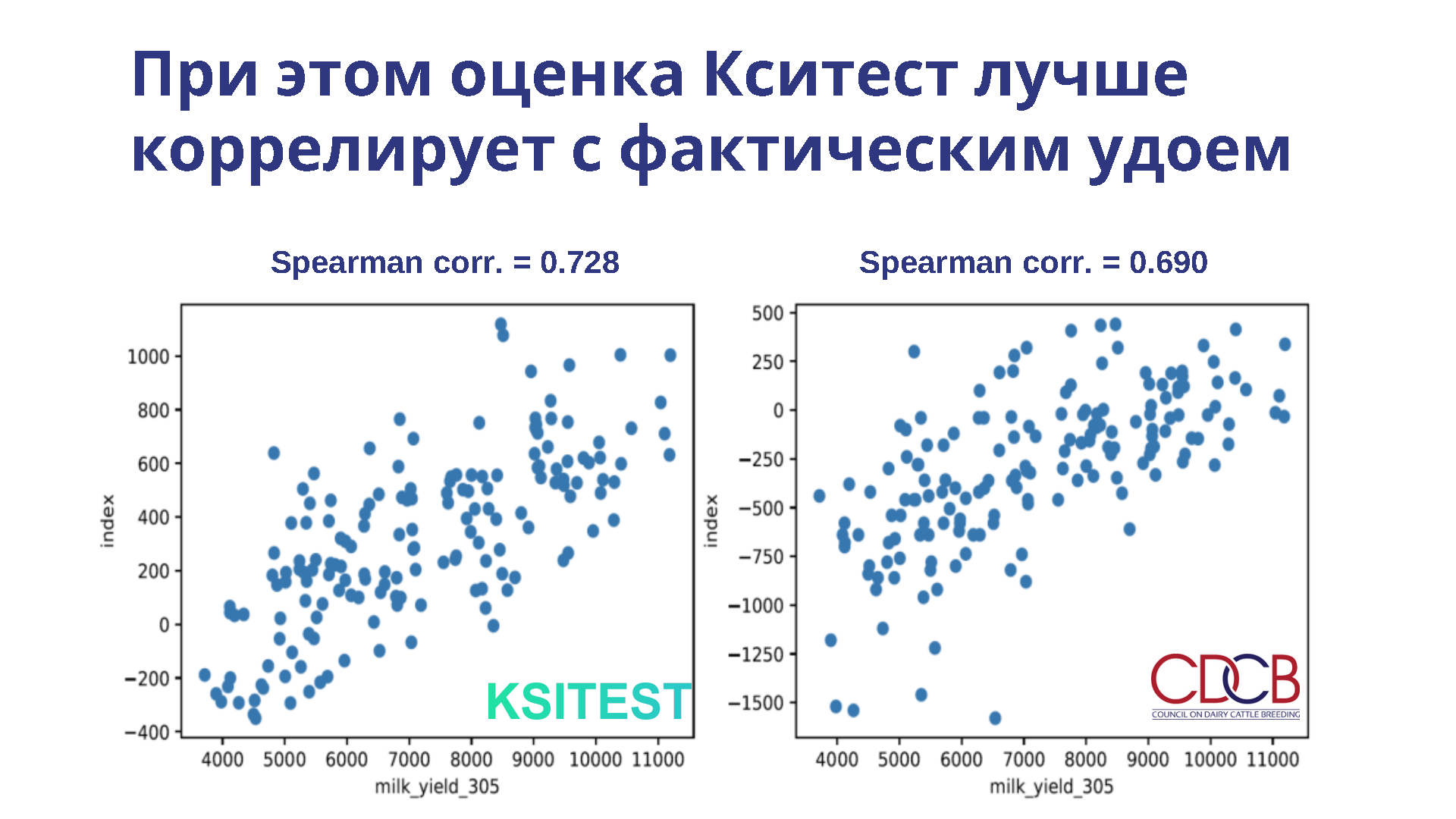
Антон:
Следующим этапом сравниваем, как наши оценки коррелируют с фактическим удоем животных. Мы провели корреляцию наших оценок с фактическим удоем и оценок CDCB с фактическим удоем. Наша оценка получилась немного выше, а значит, она немного лучше коррелирует с фактическим удоем животных, чем по CDCB. Чтобы понять, что это значит для экономики хозяйства, нужно разобраться на конкретном примере.

Возьмём три сценария, когда нам нужно отранжировать животных. Например, племпродажа, выбор в племядро, под эмбриотрансфер или сексированное семя. Эта разница в точности будет означать, что при отборе по нашей оценке для племпродажи средний удой животных, которых вы продадите, будет 4 600 кг молока за первую лактацию. При этом, если мы также отранжируем 10% худших по оценке CDCB по молоку, этот показатель будет на 449 кг больше. То есть вы продадите чуть лучших животных, чем могли бы продать.
Если мы отбираем в племядро животных, то нам нужно, наоборот, отобрать лучших, а по нашей оценке у этих животных среднее получится 9 330, по CDCB на 245 кг меньше, то есть животные немного хуже. По NM$ на 1 052 килограмма меньше. Если мы выбираем под эмбриотрансфер и сексированное семя, то есть выбираем самых лучших животных, то по нашей оценке в итоге тёлки, которых мы отобрали, получатся с удоем в 10 349 кг, а по оценке CDCB они окажутся на 1 400 кг хуже, а по NM$ на 1 600 хуже.
Дарья:
Здесь на самом деле нет никакой магии, нет такого, что лучше алгоритм или что-то ещё. Работает лучше только потому, что у нас есть данные по молоку, которое давали матери этих коров, у нас есть их тетя и двоюродные сёстры, родные сёстры и т. д. Просто больше информации. Конечно, у CDCB больше база данных, но у нас просто больше собственной информации, данных про условия среды и так далее, поэтому нам чуть лучше в российских реалиях получается видеть, какие настоящие данные нам покажет животное в этой базе.
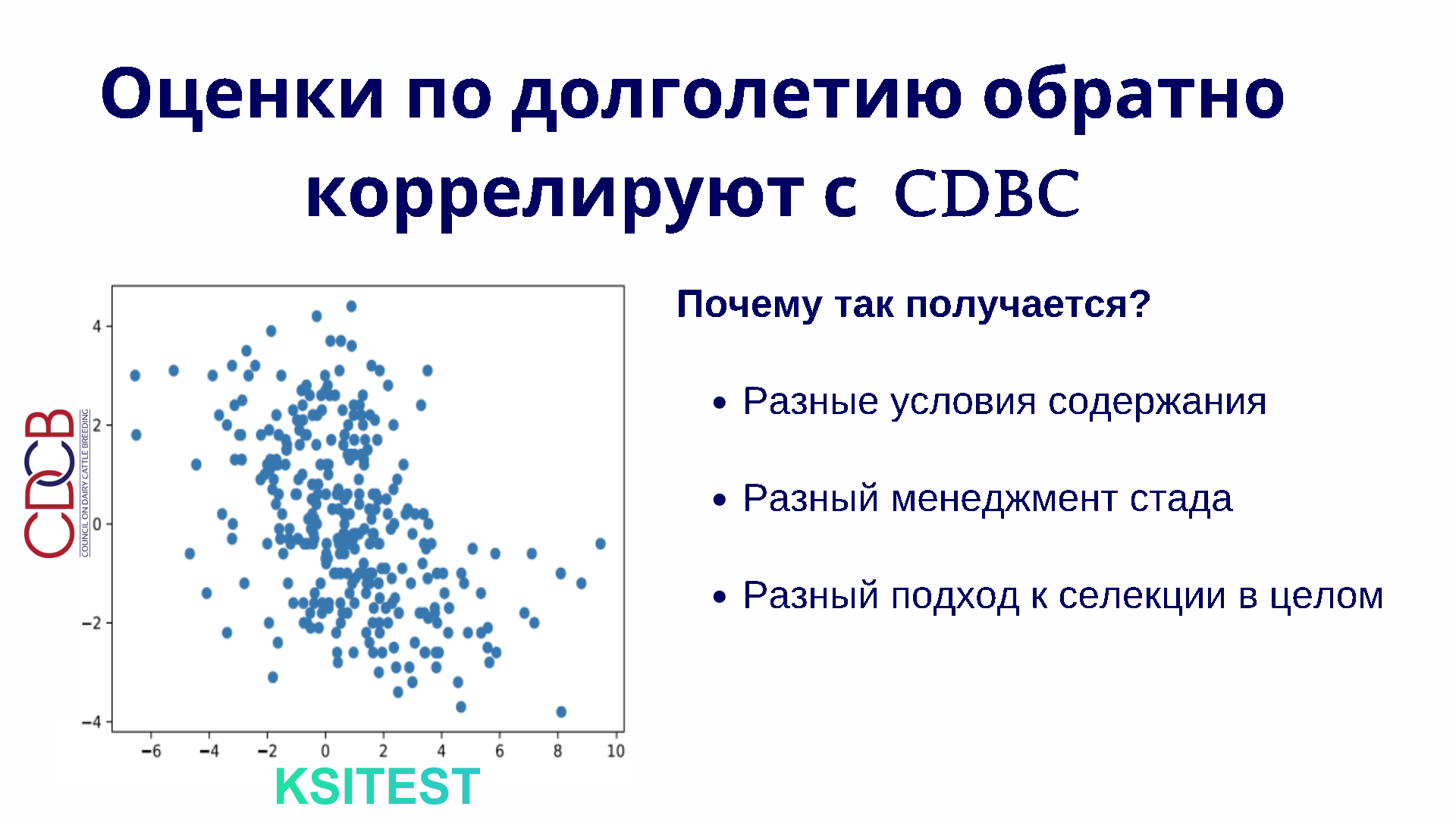
Антон:
Таким же образом, который мы только что описали, мы провели все наши оценки. Посмотрели корреляции и получили очень неожиданный результат — уникальные данные, нигде такого никогда не было.
Мы сравнили наши оценки по продуктивному долголетию с оценками по CDCB. Получили то, что наши оценки обратно коррелируют с оценками CDCB. Что это значит? Если у животного оценка по CDCB по долголетию выше, то в условиях российских реалий оно живёт меньше, то есть в нашей оценке оно имеет меньшее значение. Если оно живёт у нас дольше, то, наоборот, оценка по CDCB у него получается ниже. Почему так вообще может получаться?
Дарья:
Результат для нас был неожиданным. Всё это время мы отбирали животных по продуктивному долголетию по CDCB, а тут оказалось, что оно обратно коррелирует с нашими данными. С другой стороны, уверена, что многие селекционеры знают, откуда это берётся. Если животное очень много доят, то может ли оно очень долго жить? Нет, у нас нет условий, чтобы корова, которая давала 15 тонн, долго жила. В обратную сторону тоже работает. Если корову сколько-то доят, и она живёт долго, ну и прекрасно. Она стоит и стоит и будет стоять, пока будет доиться. При этом в США, наоборот, если есть надои 6 тонн, то считается, что мы не должны её оставлять, потому что мало молока, и она не будет приносить прибыль.
Антон:
Мы видим, что разные подходы к селекции в силу различных причин дают такие удивительные результаты.
Для чего нужны все эти оценки? Все эти оценки в итоге нужно засунуть в какой-то индекс, который поможет отбирать животных. Потому что если отбирать только по молочной продуктивности, например, то в итоге будут потеряны различные положительные качества этого животного.
Какие бывают индексы?

Условно их можно поделить на 2 группы: экономические и селекционные.
Экономический учитывает экономическую значимость каждого признака и показывает, насколько животное будет приносить больше прибыли, чем какое-то среднее животное по стаду. То есть либо в жизненном варианте, либо в годовом.
Селекционный индекс рассчитывается на основе какой-то конкретной селекционной цели и ранжирует животных в условных единицах индекса. Соответственно, чем выше у животного оценка по этому индексу, тем оно ближе к селекционной цели, которую мы преследуем. Естественно, это немного разные подходы.
Экономический индекс у нас уже есть — он был разработан для Минсельхоза Удмуртии. Селекционный индекс мы сейчас разрабатываем и скоро предоставим. Следите за нашими соцсетями.
Если же мы вообще не будем использовать индекс, а будем использовать оценку, то может произойти ситуация, когда, отбирая по чему-то одному, мы будем терять что-то другое. Когда мы не учитываем, например, долголетие, отбирая только по удою, то долголетие будет неизбежно падать.

Дарья:
На слайде представлен график одного из наших клиентов. Видно, что у них были недостаточно высокие показатели по удою. Они явно начали отбирать быков по удою, и долголетие скатилось вниз буквально за пару лет. Поэтому важно учитывать не только конкретные оценки, а смотреть на всё в целом.
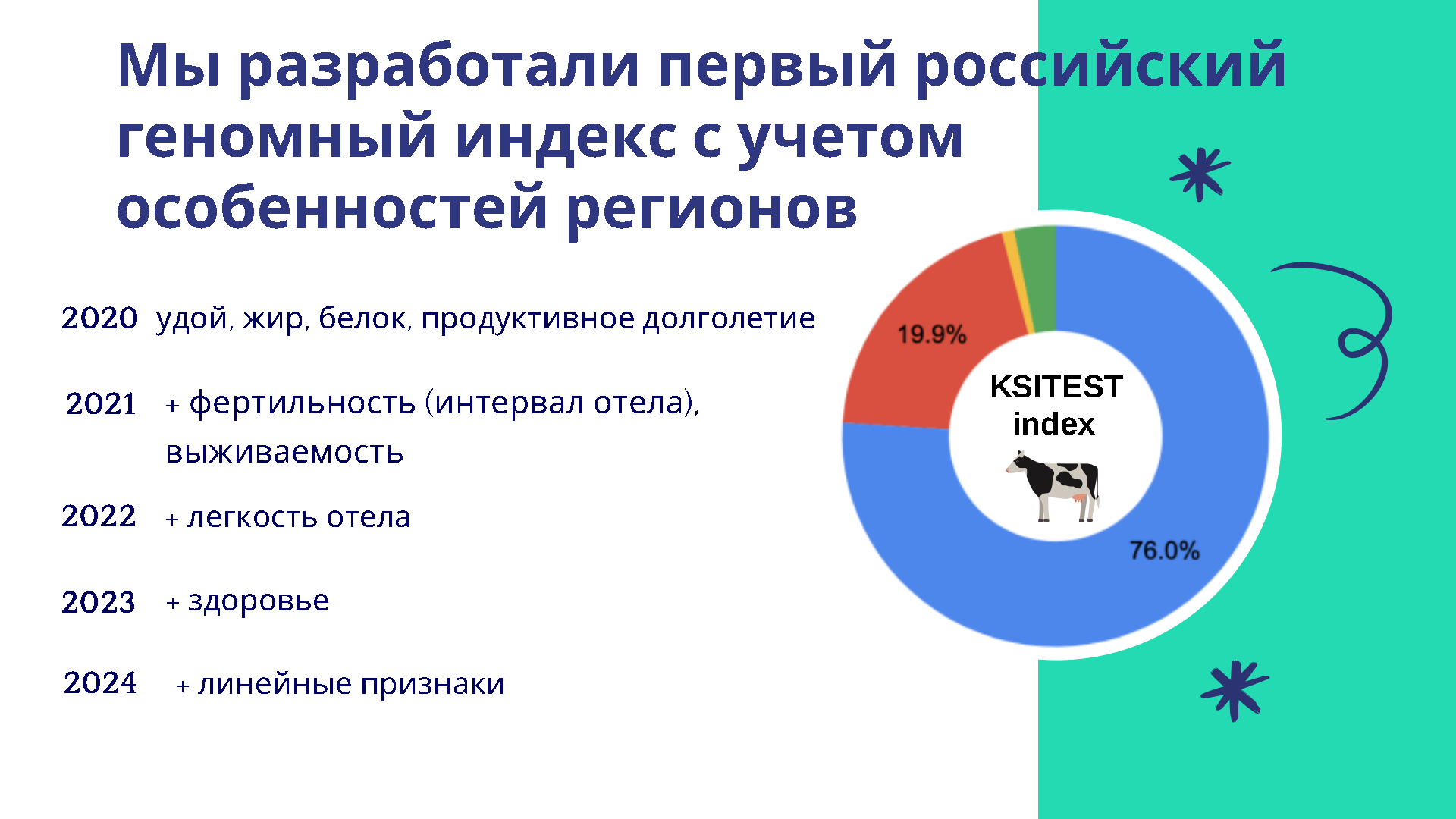
Антон:
На слайде представлен экономический индекс для Республики Удмуртия, который мы разработали. Сейчас в нём содержится шесть показателей. В конце года мы добавим ещё два. Оценки у нас уже рассчитаны. В целом мы его будем расширять, с каждым годом добавляя новые признаки. Сейчас он включает показатели удоя, жира, белка, продуктивного долголетия, скоро добавим интервал отёла и выживаемость.
Какие ещё оценки можно добавить?
Любят говорить, что российским данным вроде как не очень можно доверять, но по факту это какое-то абстрактное видение. Мы только что убедились на представленных сведениях, что точность оценки довольно высокая. Значит, есть хозяйства с хорошими данными. К тому же есть много признаков, которые нет смысла как-то подделывать или изменять, например, даты рождения, данные по осеменению или даты и причины выбытия. Даже из таких данных мы уже можем получить довольно много оценок по фертильности. Сейчас мы разрабатываем ещё оценку по фертильности, это будет оценка от отёла до первого осеменения, от отёла до плодотворного осеменения и другие. Оценки по жизнеспособности и выживаемости в различный период мы тоже сейчас разрабатываем.
Инбридинг и моногенные заболевания.
Спикер: Ксения Максимова, биоинформатик KSITEST.
Модератор: Дарья Яковишина, генеральный директор и сооснователь KSITEST.
Ксения:
Инбридингом называют скрещивание близкородственных особей. Для оценки уровня инбридинга необходимо рассчитать коэффициент инбридинга. Он отражает прирост гомозиготных пар генов у особей относительно среднего по популяции. Различают два метода расчёта инбридинга.
- Анализ по родословной (коэффициент по Кисловскому-Райту).
- Анализ по геному (протяжённый гомозиготный участок — ROH).
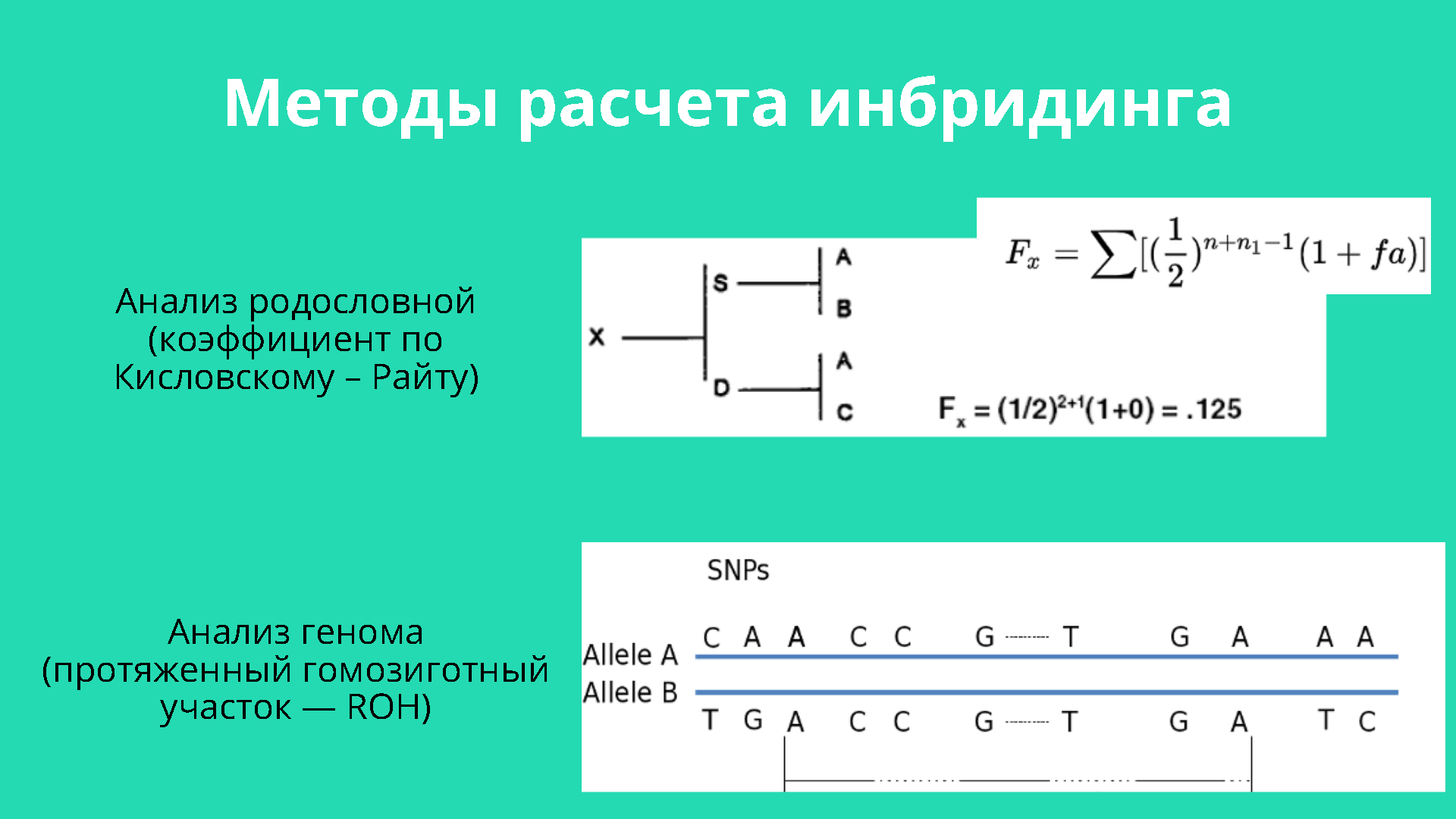
Самый распространённый анализ — по протяжённости гомозиготных участков. Анализ по родословной позволяет работать с историческими данными и не требует сложных вычислений, оборудования, но не всегда отражает действительность, потому что аллели могут наследоваться по-разному.

На слайде мы видим, что при скрещивании брата и сестры коэффициент инбридинга, который оценён по родословной, составляет 12,5%. Однако в действительности по геному коэффициент инбридинга может быть как 0%, так и 46%, и только геномные методы позволяют зафиксировать такое различие.
Почему могут быть такие отличия?
Наследование аллели может иметь разные сценарии, и здесь мы видим, что это связано с кроссинговером. Могут наследоваться разные участки аллелей, и из-за этого получаются разные комбинации, разные наборы. Можем получить, как 0%, когда не появляется пересечения у двух аллелей, так и 46%.

При ведении селекции уровень инбридинга растёт, так как мы накапливаем благоприятные гомозиготные пары генов. Но с геномной селекцией рост инбридинга увеличивается, это связано с тем, что сокращается поколенческий интервал. Стоит отметить, что если без геномных методов инбридинг рос неэффективно и сопровождался увеличением носителей заболеваний, в текущей ситуации геномные методы позволяют инбридингу расти более эффективно, избегая такого большого накопления носителей заболеваний.
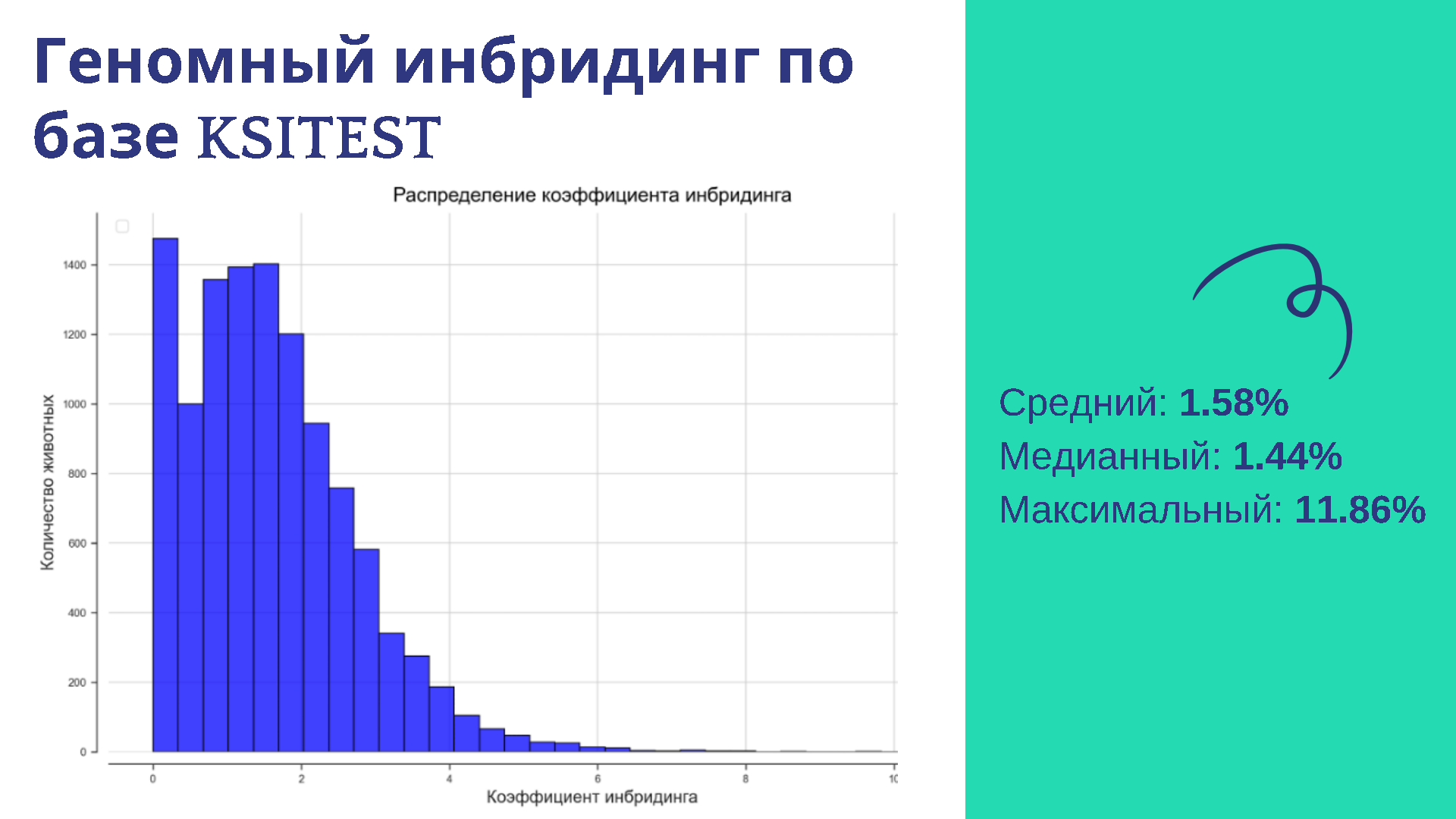
Мониторинг инбридинга — это важно и необходимо. Показываем ситуацию по нашей популяции, и видно, что коэффициент инбридинга, в основном, приходится на интервал от 0 до 3%. Среднее значение — 1,58%. Также есть одно животное с коэффициентом инбридинга почти до 12%, однако по родословной у него 25%. Здесь также мы наблюдаем разницу.
Дарья:
Знаю, что многие селекционеры в России работают над тем, чтобы инбридинг не рос. Всё получилось, инбридинг в России достаточно низкий. Мы видим, что у подавляющего числа животных инбридинг ниже 6%. У более 85% ниже 4%. То есть фактически проблема высокого инбридинга в России не стоит. Мы взяли самые точные геномные данные, основанные на 15 000 генотипов.
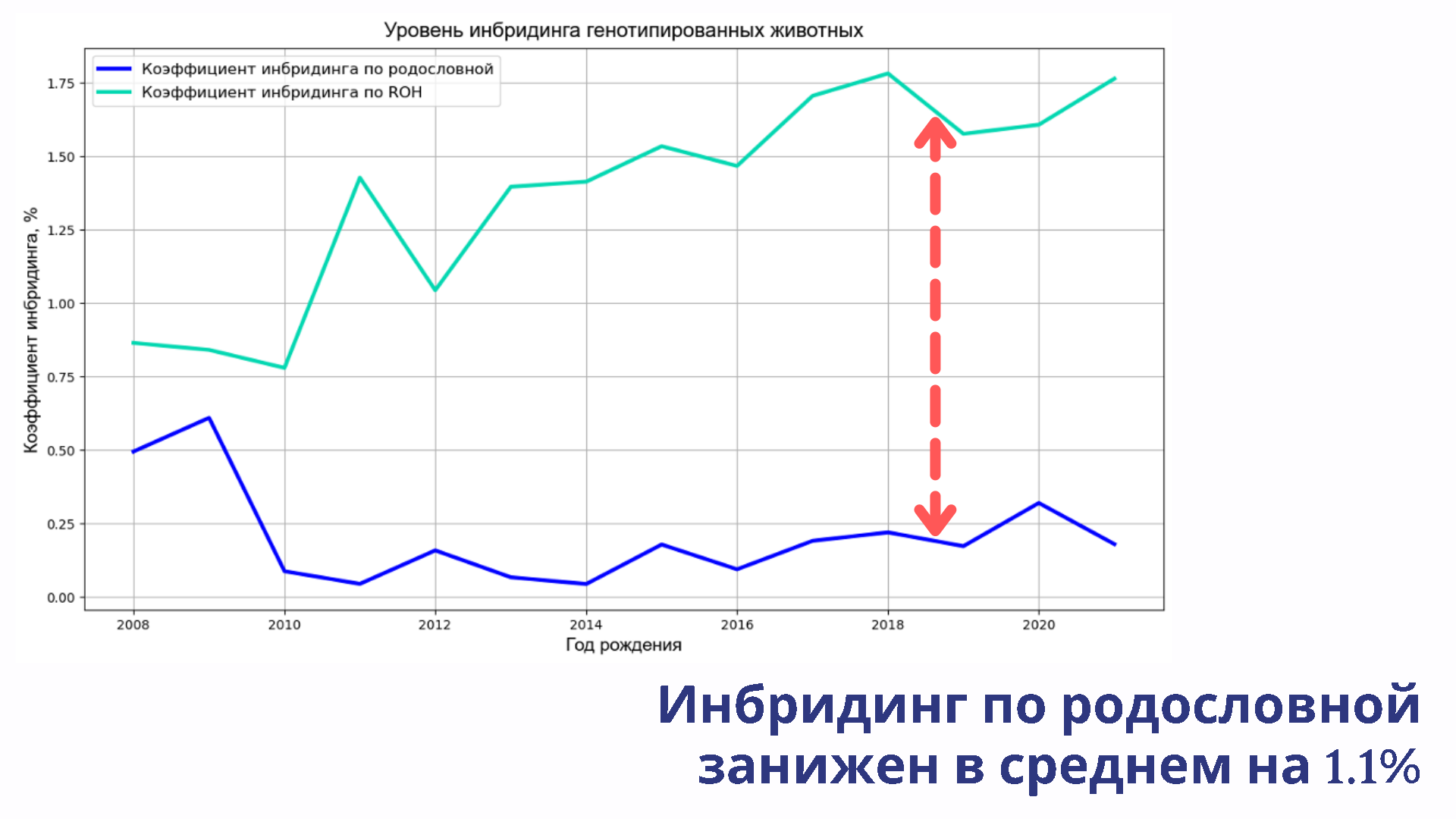
Ксения:
В среднем инбридинг по родословной занижает реальное значение коэффициента инбридинга. На нашей выборке это значение в среднем приходится на 1,1%.
Носительство моногенных заболеваний.

В селекции важно мониторить ситуацию по количеству животных и их носителей. Здесь мы привели таблицу со сравнением данных по Канадской ассоциации и по нашим данным. Видно, что процент носительства в нашей популяции составляет 24,1%. В Канаде — 35,6%. Также здесь можно отметить, что самое распространённое моногенное заболевание в Канаде — это дефицит холестерина, или HCD. Он достигает по канадской статистике 14,3%. У нас это число — 3,1%. В Канаде много лет ведётся геномная селекция, но тем не менее у нас пока доля всех носителей довольно низкая.
Дарья:
Хочется обратить внимание, что доля всё равно 24%. Мы видим, что сейчас по разным хозяйствам значения носителей варьируются примерно от 20 до 25%. Несмотря на то, что это ниже, чем в Канаде. Нужно понимать, что это четверть животных. Главный здесь вывод, что носителей моногенных заболеваний достаточно много. Когда мы отбираем быков, важно обращать внимание на то, кого с кем скрещиваем, и на новые моногенные заболевания. Потому что, например, на пятый гаплотип раньше не делали проверки, и вот мы видим, что у нас достаточно много быков, которые были с таким гаплотипом. Мы это можем видеть сейчас, потому что у нас есть их потомки, и из них примерно 25−50% носителей. То есть мы видим, что он действительно сам являлся носителем.
Геномная селекция для переработчиков молока.
Спикер: Григорий Юрков, консультирующий зоотехник и руководитель группы сырого молока Valio.
Модератор: Дарья Яковишина, генеральный директор и сооснователь KSITEST.
Григорий:
Сейчас на российском рынке достаточно часты ситуации, когда или у производителя сырого молока есть собственная переработка, или переработчику сырого молока принадлежит какая-то ферма или фирма. Одна и та же организация занимается и производством пищевых продуктов, и производством сырого молока. Поэтому важно сказать, насколько геномная селекция может быть полезна в вопросе качества молока. Тема чрезвычайно обширная, здесь есть много о чём рассказать, но мы хотели бы сконцентрироваться на двух моментах: содержание компонентов в молоке, жира и белка, и сыропригодность.

В последние годы наметился некий тренд на снижение содержания компонентов в молоке. На слайде приведены данные центра изучения молока The DairyNews. Этот тренд более заметен у крупных производителей, и он не может не беспокоить переработчиков, поскольку содержание компонентов в молоке определяет большое количество показателей эффективности.
Что можно сделать, если переработчик и организация или производитель сырого молока принадлежат одному собственнику и глубоко взаимодействуют с друг другом? Дело в том, что геномная селекция на содержание жира и белка в молоке может переломить такого рода негативный тренд.

На слайде представлены данные департамента сельского хозяйства США. Здесь видно, что некоторую стабилизацию и даже некоторое падение содержания жира, которое происходило в США, начиная с 2013 года, удалось переломить, и содержание жира растёт.
Сыропригодность сырого молока зависит от генов CSN3 и CSN2.
Как можно попытаться бороться с плохой коагуляцией? Мы вносим в смесь уплотнитель, но его можно вносить только до определённого уровня. Для того чтобы предотвратить плохую коагуляцию, потому что дальше начинаются проблемы с консистенцией и со вкусом, можно в том числе задействовать геномную селекцию.
Услуги, предоставляемые компанией KSITEST, позволяют определять варианты двух генов, которые кодируют каппа-казеин и бета-казеин, — это гены соответственно CSN3 и CSN2. Желательные варианты этих генов приводят к более хорошей и быстрой коагуляции, более плотному сгустку.

Мы провели сравнение количества животных, которые являются носителями желательных вариантов гена CSN3, кодирующего каппа-казеин. В российской популяции оказалось 34% носителей желательного аллеля и только 6% носителей желательного генотипа, в том время как в Восточной Европе эти цифры 54% и 12%. Таким образом, ведя целенаправленную селекцию на желательные варианты гена CSN3, можно в том числе повысить сыропригодность сырого молока.


